




摩登7平台合作客户/
拜耳公司 |
同济大学 |
联合大学 |
美国保洁 |
美国强生 |
瑞士罗氏 |






相关新闻Info
推荐新闻Info
-
> 影响狭缝间氢键流体气液平衡界面张力的因素有哪些(三)
> 影响狭缝间氢键流体气液平衡界面张力的因素有哪些(二)
> 影响狭缝间氢键流体气液平衡界面张力的因素有哪些(一)
> GA、WPI和T80复合乳液体系的脂肪消化动力学曲线、界面张力变化(四)
> GA、WPI和T80复合乳液体系的脂肪消化动力学曲线、界面张力变化(三)
> GA、WPI和T80复合乳液体系的脂肪消化动力学曲线、界面张力变化(二)
> GA、WPI和T80复合乳液体系的脂肪消化动力学曲线、界面张力变化(一)
> 表面张力实验、接触角实验分析抑尘试剂对煤的润湿结果
> 摩登7表面张力仪研究烧结矿聚结行为
> 基于界面张力和表面张力测试评估商用UV油墨对不同承印纸张的表面浸润性差异(三)
大幅提高新药筛选速度,对包含110亿种化合物的虚拟库进行快速筛选
来源:生物世界 浏览 1299 次 发布时间:2022-09-16
高通量筛选(HTS)和虚拟配体筛选(VLS)的标准库历来被限制在不到1000万个可用化合物,与潜在的1060个类药物化合物的巨大化学空间相比,这只是一小部分。标准HTS和VLS的这种局限性减慢了药物发现的速度。
后来,包含数十亿化合物的虚拟库被开发出来。但随着虚拟库的规模增加到数十亿,筛选库中所包含的分子在计算上变得不切实际,而且成本过高。比如,使用1个CPU筛选100亿个化合物可能需要3000年以上(以每个化合物10秒的标准速率对接)。
因此,需要更有效的方法来搜索大规模的化合物库。
2021年12月15日,美国南加州大学、东北大学和北卡罗来纳大学教堂山分校的研究团队合作,在Nature发表了题为:Synthon-based ligand discovery in virtual libraries of over 11 billion compounds的研究论文。
该研究开发了一种从包含110亿种化合物的虚拟库中识别潜在药物分子的创新方法,并以3个目标蛋白的抑制剂筛选为例,展示了该方法的性能。

用于巨大化学库的虚拟筛选方法
研究团队开发了一种被称为V-SYNTHES的方法(virtual synthon hierarchical enumeration screening,虚拟合成子分级枚举筛选),大大减少了在这些库中搜索潜在hits时需要评估的分子数量,使用的计算资源是标准方法的百分之一。
该方法可轻松扩展以适应组合库的快速增长,并且可能适用于任何对接算法。
V-SYNTHES的工作流程和结果
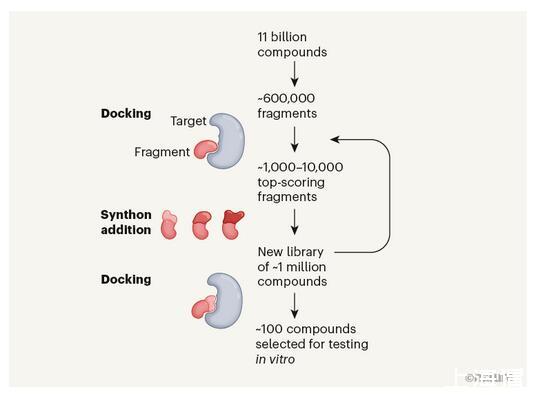
图1一种处理巨大化学库的虚拟药物筛选方法
该方法的流程如下
1.首先建立一个小型的虚拟库。从110亿个分子库中选择了大约60万个片段,这些片段代表整个虚拟库中存在的所有不同的骨架。称之为最小列举库(minimal enumeration library,MEL)。
2.将MEL库中的片段与3个目标蛋白对接,计算这些片段与每个蛋白的结合亲和力。
3.选择对接分数最高的1,000-10,000个片段,并向它们添加了合成子(synthons,分子的小片段),创建了一个约有100万个分子的新库。
通过重复对接和添加合成子的步骤,筛选几百万个化合物来确定hits。随着每一次迭代,每个化合物的大小都会随着分子变得更加完整而增加。
4.几千个排名靠前的VLS化合物经过PAINS、物理化学性质、药物相似性、新颖性和化学多样性的后处理过滤,最终选择有限的化合物集(通常是50-100个)进行合成和实验测试。
作者发现,在V-SYNTHES预测的与这些受体结合并在低化合物浓度下抑制其活性的前60个化合物中,约有三分之一确实在体外显示了这种效应。这个"hit获得率"大约是作者使用的标准方法的两倍,而V-SYNTHES需要的计算资源比这些方法少100倍。
作者随后在一种叫做ROCK1的激酶上测试了V-SYNTHES,并报告了28.5%的hit获得率。在被选中进行合成和体外测试的21个最有希望的化合物中,有6个可以与ROCK1酶结合,并在化合物浓度低于10微摩尔时对其进行抑制。这些化合物可以成为药物发现计划中进一步优化的合适线索。
V-SYNTHES的价值和意义
V-SYNTHES代表了药物发现初始阶段的两种主要方法(基于结构的药物设计和基于片段的药物设计)的结合。在基于结构的设计中,分子的结构特征及其与靶点的相互作用被用来指导设计过程。在基于片段的药物设计中,分子基团被添加到最初因其潜在活性而被确定为有前途的片段中。
这篇论文为从现在可用的大型化合物库中识别生物活性分子铺平了道路,使用的计算资源和时间仅为标准虚拟筛选方法的一小部分,而且成功率更高。最重要的是,该方法的计算成本随着使用的合成子的数量而增加,而不是随着初始的主要库的大小而增加。因此,随着现成的化合物库及其组合的不断增加,该方法将继续具有计算上的可行性。
虽然该方法使用ICM-Pro对接并应用于Enamine REAL Space库,但基于迭代合成子的筛选算法可以在任何可靠的基于对接的筛选平台上实现,并在任何可以表示为骨架和合成子组合的超大型库中使用。在操作过程中可能需要对算法的某些参数进行自定义调整以获得最佳性能,从而为进一步探索该方法开辟了许多途径。
V-SYNTHES的扩展性意味着用户将能够在特别大的虚拟化合物库中搜索并找到具有生物活性的分子。该方法不能保证找到最好的hits,但这可能并不重要,因为次优的hits往往为药物开发过程提供了良好的起点。
不过从长远来看,虚拟筛选的更大问题是,无论该方法如何快速,其结果都取决于对接步骤的准确性。如同所有的虚拟筛选方法一样,V-SYNTHES识别良好hits的能力取决于对接分数的准确性,需要有真正可靠的对接分数被开发出来。